What the heck is homomorphism?
Hello. Continuing my dive into the nature of abstractions in software engineering, I’ve reached yet another rabbit hole.
Yes, rabbit holes turn out to be recursive in nature.
So, last time we found out that the most accurate definition of abstraction seems to be the words of Edsger Dijkstra:
Being abstract is something profoundly different from being vague… The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise.
Thanks to Jimmy Koppel, it turns out that Professor Gerald Jay Sussman rightly considers abstraction too broad a “suitcase term” that denotes too many things. However, he sees two related definitions that apply to software engineering.
Definition 1 - “giving names to things produced by the second definition”; Definition 2 - Well, it is tough stuff, following from the Fundamental Theorem of Homomorphisms.
As it is tough, and I promised to do my best in writing as simply as possible… I will try, but sorry, I will most likely fail again :)
But it is so interesting!
Fundamental Theorem on Homomorphisms for Dummies
Okay, take a look at this beautifully cryptic diagram:
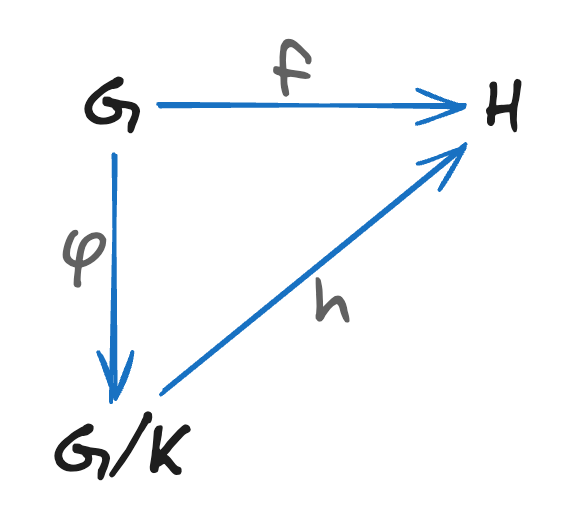
Let’s break it down.
Imagine you have a collection of shapes: circles, squares, and triangles.
Each shape can be either red, blue, or green.
Let’s define an operation called “change color” which, obviously, changes the color of any of your shapes to another one.
So, G represents all collections of our shapes of different colors.
And f is our “change color” operation.
Potentially, we can have sets of shapes in G, for which f will do the same transformation.
For example, it can turn out that f will change color to specific one based on shape form so we will have at least three groups:
- Circles -> Change color to green;
- Squares -> Change color to blue;
- Triangles -> Change color to red.
At least, because we can already have green circles and so on, so
fwill not change anything, but let’s not take that into account now.
Each of our groups we select into a list, and we obtain the so-called kernel ϕ, which is a list of our “group lists.”
So, each list in our kernel consists of shapes that are “alike” by the f operation, meaning this operation treats shapes the same way.
But, the thing is that we consider each such nested list to be a representation of a conditional f-shape.
In some sense, we can call such representation “homotopy type.” But, of course, “homotopy type” is not a standard term of “Homotopy Type Theory.” We are just making analogies here.
And here we get another thing from our diagram - the Quotient Set, which is represented on it as G/K.
G/K represents a generalization of G by the f operation.
And finally, after applying our f operation, all shapes from our groups changed their colors, so we get a new set.
This new set, denoted as H, is the set of all shapes turned to another color by the f operation.
Now, putting it all together, the fundamental homomorphism theorem states that G/K behaves the same as H: a set of different representations of shapes can be manipulated in the same way as a single specific shape.
G/Kis isomorphic toH.
We know this thing as duck typing: if something looks like a duck, swims like a duck, and quacks like a duck, then we consider it to be a duck, so we can manage it with just one operation: “looks_like,” “swims,” or “quacks.”
The interesting thing is that Professor Sussman emphasizes G/K, but not the whole theory as it is.
From his point of view, we are getting another beautiful definition of Abstraction, and it might be formulated like:
Abstraction is the principle or scheme of uniting different representations that behave the same way under a given operation.
It looks like this definition varies from the dozens of other definitions of Abstraction, yet it indeed is compatible with almost any of them.
Because this idea is really powerful - it allows us to consolidate all the complex relationships between various implementations and their common abstract domain into a single “reflection.”
In fact,
ϕis the “reflection” of abstraction, whereasGandG/Kare concrete and abstract subject areas, respectively.
How to live with it
This potential link between “software-ish” abstractions and Abstract Algebra with Type Theories feels really sweet, but does it give us any evident and applicable mechanism which can help us to improve our mostly boring daily coding?
Well, “evident” - no. Applicable - I do believe yes. Let me explain.
Abstract interpretation does not give us any sharp tools to fight with inaccuracy. In the previous post, I found that any correct formal definitions of abstractions (meaning in concrete subjects) essentially every time give us the conclusion - “this thing could be just anything.”
Not really accurate, when implementing something we want to be as much accurate as possible.
And still, having in mind such sane definitions of Abstractions one of which we just discovered gives us the possibility to look at the subjective area from a completely different point of view.
Conversely, not having such knowledge leaves us more “blind,” forcing us to move through the space of some domain in almost complete darkness. Yes, I do believe it is a good metaphor for our case.
Just try to imagine how many homomorphisms we might end up with by the end of the day, and how diverse they could be even for the same G if we design our system and its operations carelessly.
Do you feel it? This is literally the source of nightmares in poorly designed systems.
Will thinking only in terms of methods and patterns, such as those we have from the GoF, help with this?
I am not quite sure, because it feels that while we keep talking about patterns and other mainstream concepts, we are losing something really important.
The value
So the main conclusion I can extract from today’s topic might be obvious to you already.
I think the most universal and truly safe way of abstracting domain ontology from the very first steps of any project is to define the most rough, generalized, and obvious entities as Abstract Data Types based on operations on them, and not on their “names”.
Of course, we will most likely in every case proceed with detailing the operations on our ADT’s, but we should start with the minimum number of operations designed as possible.
Considering that if f: G -> H is a homomorphism for a specific operation, it means that f preserves that operation.
Different operations might have different corresponding homomorphisms, but, of course, not necessarily for every possible operation on G.
And still, I am not mathematician, but this “might” feels like… likely.
I think that amount of possible homomorphisms is really matters.
Defining, “producing” some type/class will inevitably produce some operation for them, just because some class should do something.
When we are not thinking about operations in the first place, we might end up with a cumbersome and complicated type-system/class-hierarchy, trying to dance around polymorphism, method overloading and other ugly things.
So why should we design systems thinking about phenomena/classes/entities if the operation is the essence of homomorphism?
From this, it directly follows that calculations are the “backbone” of every software system, so it should be designed based on the operations.
It is so stupidly obvious, yet we so often stupidly ignore it, getting lost in vague “things.”
It will not work in designing a complex system for big and complex technical specifications! - we could fairly argue.
And it is true. Luckily, we have incredibly useful methods of analysis and designing Abstract Data Types systems that make this process easier and even kind of straightforward.
Like the one proposed by Bertrand Meyer.
But it is a completely different story, which I will cover in another blog post.
Stay tuned, and remember -> calculations.